
Understanding Microkernel Architecture


There’s a class of problems in software development that are fundamentally about variability. Not scale. Not throughput. Variability — where the same process needs to behave differently depending on context, region, customer, or configuration. Layered architecture (discussed in the previous article) won’t save you here. Microservices might be an overkill. But microkernel architecture, also called plug-in architecture, is purpose-built for exactly this.
It’s one of those patterns that looks deceptively simple at first glance, then turns out to be surprisingly powerful once you understand what you can actually do with it.
The Structure
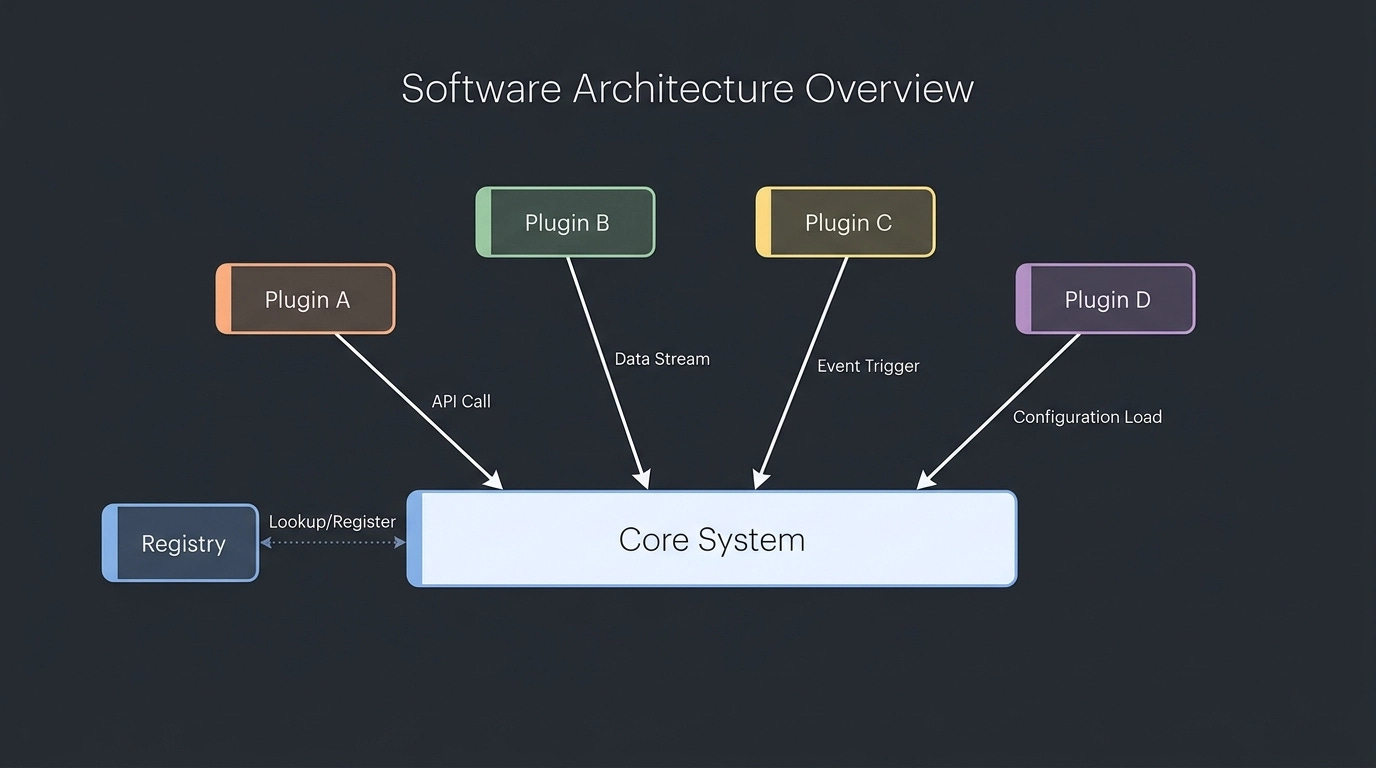
Microkernel architecture has two types of components: the core system and plug-in modules.
The core system is formally defined as the minimal functionality needed to run the system. A more useful way to think about it for business applications is the happy path — the general workflow, the baseline behavior, the thing the system does when nothing unusual is happening.
Plug-in modules contain either additional functionality or, more importantly, the volatile areas of the application. The parts that change. The parts that differ by jurisdiction, customer, configuration, or business rule. These are standalone components. Crucially, they don’t know about each other.
The examples that come to mind immediately are product-oriented: an IDE like Eclipse, which is essentially a glorified text editor until you start loading plug-ins, or a web browser, which is a lightweight shell that extensions bring to life. Your instance of Eclipse looks completely different from mine because of the plug-ins each of us has installed.
But microkernel isn’t just for products. This is where most people stop thinking too early.
The Business Case: Claims Processing
Consider an insurance claims processing system. What makes claims processing genuinely hard isn’t the steps involved in processing a claim — it’s the jurisdiction rules. Every state has different rules. Massachusetts offers free windshield replacement on any rock strike. Another state allows one replacement. Some allow none. That’s one rule out of thousands that vary across every state an insurance company operates in.
In a traditional monolithic architecture, those rules are baked into the codebase. Change a rule for Texas, and you’re touching the system. You can’t be certain you haven’t broken anything else. Testing the change means testing everything.
Now apply microkernel thinking. The core system handles the general claims workflow — the happy path. Each state’s rules live in a plug-in module. When your company expands to Georgia, you plug in the Georgia module. When you decide to exit Texas, you unplug it. When New York’s rules change, you modify and redeploy the New York plug-in. Nothing else in the system is touched. Nothing else needs to be tested.
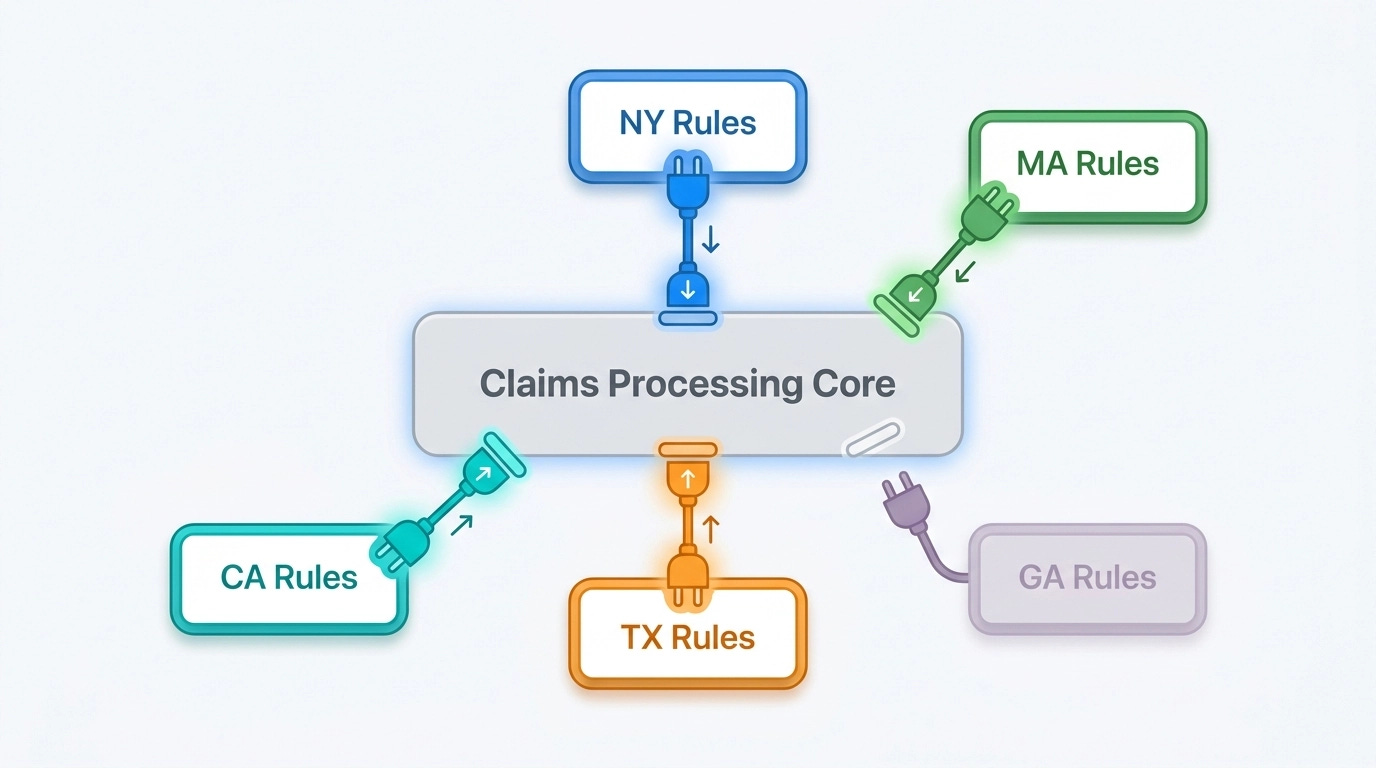
That’s the real power of the pattern. The volatility of the application — the parts that change frequently — is isolated in plug-ins that are each independently testable and independently deployable.
The Registry and Contracts
There are two implementation details that add complexity here but are non-negotiable.
The registry is how the core system knows what plug-ins exist and where to find them. This doesn’t need to be infrastructure-heavy. It can be as simple as a HashMap in Java or a plain dictionary in any other language — mapping a context key to a class name or reference. When a plug-in is added, the registry is updated. When it’s removed, the entry comes out. That’s it. You don’t need OSGI, Zookeeper, or any dedicated registry tool unless your requirements actually demand that scale.
Contracts define the interface each plug-in must implement: the method signature, the input it receives, the output it returns. The goal is stability of the contract over time, because every time the contract changes, the core system changes — and that’s exactly what you’re trying to avoid. The whole point is to push volatility outward and keep the core system stable.
When a third-party plug-in arrives with a different contract, the right answer isn’t to modify the core. Add an adapter that translates the foreign contract into your standard one. The core system stays clean.
A concrete illustration of what a contract looks like in practice: imagine a source code validation tool where the core simply reads a Java file, parses it line by line, and outputs a report. Every validation check is a plug-in. The contract specifies an execute() method that accepts the filename and list of source lines, and returns a report string. The core iterates through the registry, instantiates each plug-in class, calls execute(), and prints the result. What each plug-in does with the source lines — header checks, SQL call patterns, interceptor usage, property formatting — is entirely up to that plug-in. The core has no idea, and it doesn’t need to know.
This separation of concerns is the discipline that makes the pattern work. The core doesn’t own the report format. It doesn’t know about SQL conventions. Each plug-in owns its own domain completely.

Where the Pattern Pays Off
The architectural characteristics tell the story clearly.
Agility, testability, and deployability all score well — and the reasoning for each is the same. Volatility is isolated. When a rule changes, one plug-in changes. That’s what you test. That’s what you deploy. The risk surface is contained.
Deployability is worth calling out specifically because it scores a thumbs-up here while it scores a thumbs-down for a standard layered monolith — even though both are monolithic architectures. The difference isn’t about how easy it is to deploy. It’s about the risk of deployment. In microkernel, when you change the New York rules, you’re deploying a change that by design can’t have broken the Texas rules or the Massachusetts rules. That isolation is architectural, not incidental.
Performance and scalability don’t score well, and that’s expected. This is a monolith. If you need horizontal scalability or ultra-high throughput, microkernel isn’t the pattern that gets you there. Other patterns handle those characteristics better. Choosing microkernel means you’ve consciously decided that agility and contained variability matter more to you than raw scale.
Simplicity and cost score well. There’s no exotic infrastructure required. No distributed systems complexity. No service mesh. If your primary problem is managing variability and isolating change, microkernel gives you a lot of capability for relatively low overhead.
Knowing When to Reach for It
The pattern fits when you can identify a clear “happy path” at the center and a set of variations or extensions that orbit it. The key question to ask is: where does the volatility actually live in this system?
If the answer is “in the rules, the configurations, the per-client behavior, the jurisdiction-specific logic” — and those things change independently — you have a good candidate for microkernel. The pattern formalizes that volatility into a first-class architectural concept rather than letting it sprawl through the codebase.
If your volatility is more about scale, throughput, or service-level independence across a large distributed system, other patterns — event-driven, microservices — will serve you better.
The mistake to avoid is assuming that because this pattern produces a monolith, it’s somehow a compromise or a stepping stone. For the right problem, microkernel is the right answer. Cheap to build, relatively simple to understand, agile in the face of change, and testable by design.
Part of a series based on the O’Reilly Software Architecture Fundamentals course by Mark Richards and Neil Ford. Not sponsored or affiliated — just a resource I genuinely find useful. If you want to go deeper, O’Reilly Learning offers a 10-day free trial with access to courses, books, and hands-on labs.