
Understanding Layered Architecture
The Pattern That Started Everything

Every architectural journey has a starting point. Before you can reason about microservices, event-driven systems, or space-based architectures, you need to understand the pattern that’s been running the industry for decades — the layered architecture. It’s not glamorous. It doesn’t win conference talks. But it’s the foundation that everything else is reacting to, and understanding it deeply is non-negotiable for anyone who calls themselves an architect.
From Chaos to Structure: The Big Ball of Mud Problem
Before layered architecture, there was — nothing. Or more accurately, there was spaghetti. Imagine a visualization of a software project where thousands of classes are connected to each other in every conceivable direction. Every dot on the edge is a class. Every bold red line between them is a dependency. Change one class, and you trigger a ripple effect through 14 others — each of which triggers its own ripple. That, in architectural terms, is the Big Ball of Mud.
People don’t choose the Big Ball of Mud. They fall into it. When there’s no deliberate structure, code organizes itself around convenience rather than responsibility. And convenience at scale becomes a maintenance nightmare.
Layered architecture is the natural response. Instead of one giant bucket of code communicating in every direction, you organize everything into well-defined layers of responsibility.

The Classic Four-Layer Structure
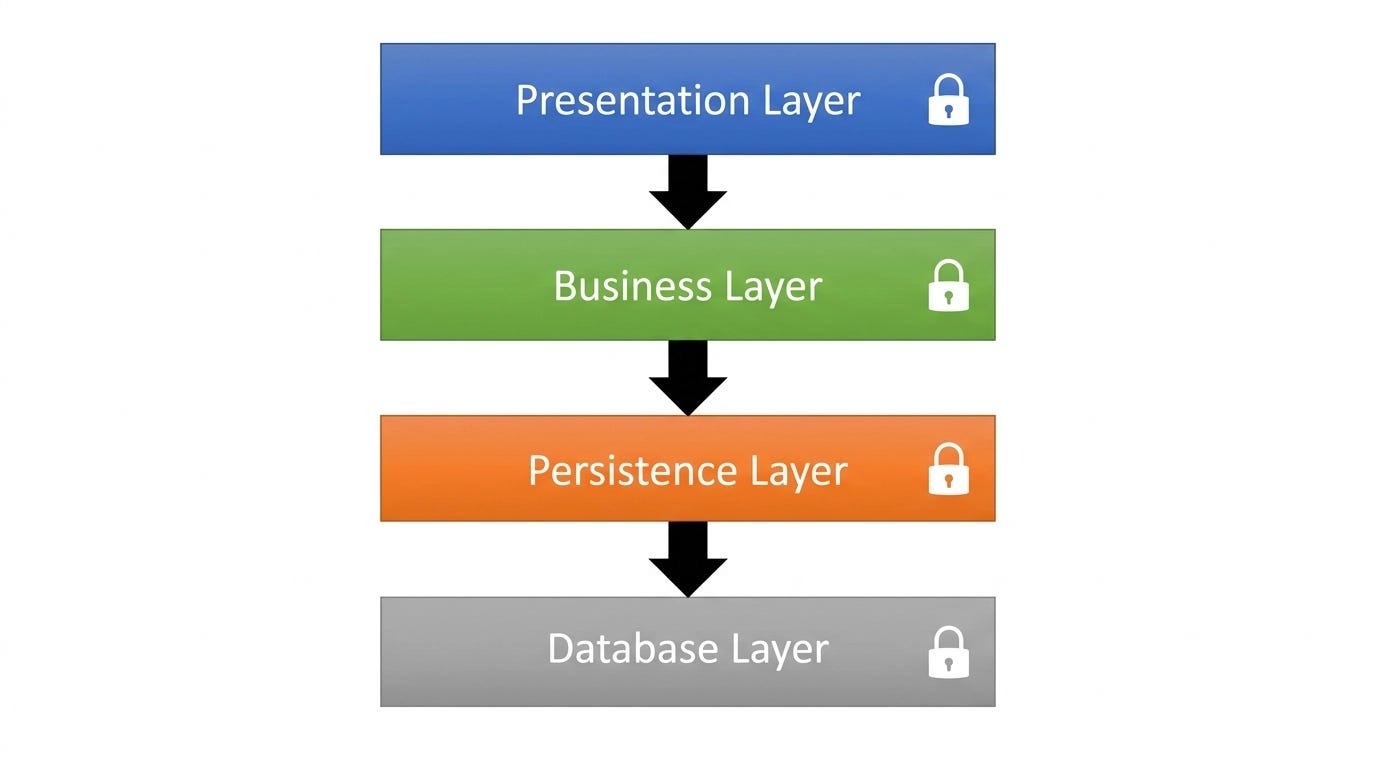
The canonical layered architecture typically looks like this, top to bottom:
Presentation Layer — Everything the user sees and interacts with
Business Layer — Business logic, rules, and workflows
Persistence Layer — Object-relational mapping, data access abstractions
Database Layer — The actual data storage
Each layer has a clearly defined job. Presentation doesn’t know how data is stored. The database layer doesn’t care about business rules. This is the power of the model: code that belongs together, stays together.
When you need to change how persistence works, you know exactly where to go. When you need to swap out the database from Oracle to SQL Server, the blast radius is contained to the bottom two layers — if the architecture is well-designed, those changes shouldn’t propagate above the persistence boundary.
The “Closed Layer” Principle
One of the most important concepts in layered architecture — and one that gets violated constantly — is the idea of closed layers. A closed layer means that a request entering the architecture must pass through every layer sequentially to reach its destination. To get to the persistence layer, you must pass through the business layer first. There are no shortcuts.
This isn’t bureaucracy for its own sake. Closed layers create isolation. They reduce coupling between distant parts of the system. They’re what give you the ability to swap components without cascading failures.
Think of it this way: if your presentation layer can talk directly to your database, your database schema is now permanently tattooed into your UI code. Want to change the database? Now you’re also changing the presentation layer. Suddenly, nothing is isolated from anything else. You haven’t built a layered architecture — you’ve built a structured Big Ball of Mud.
The Architecture Sinkhole Anti-Pattern
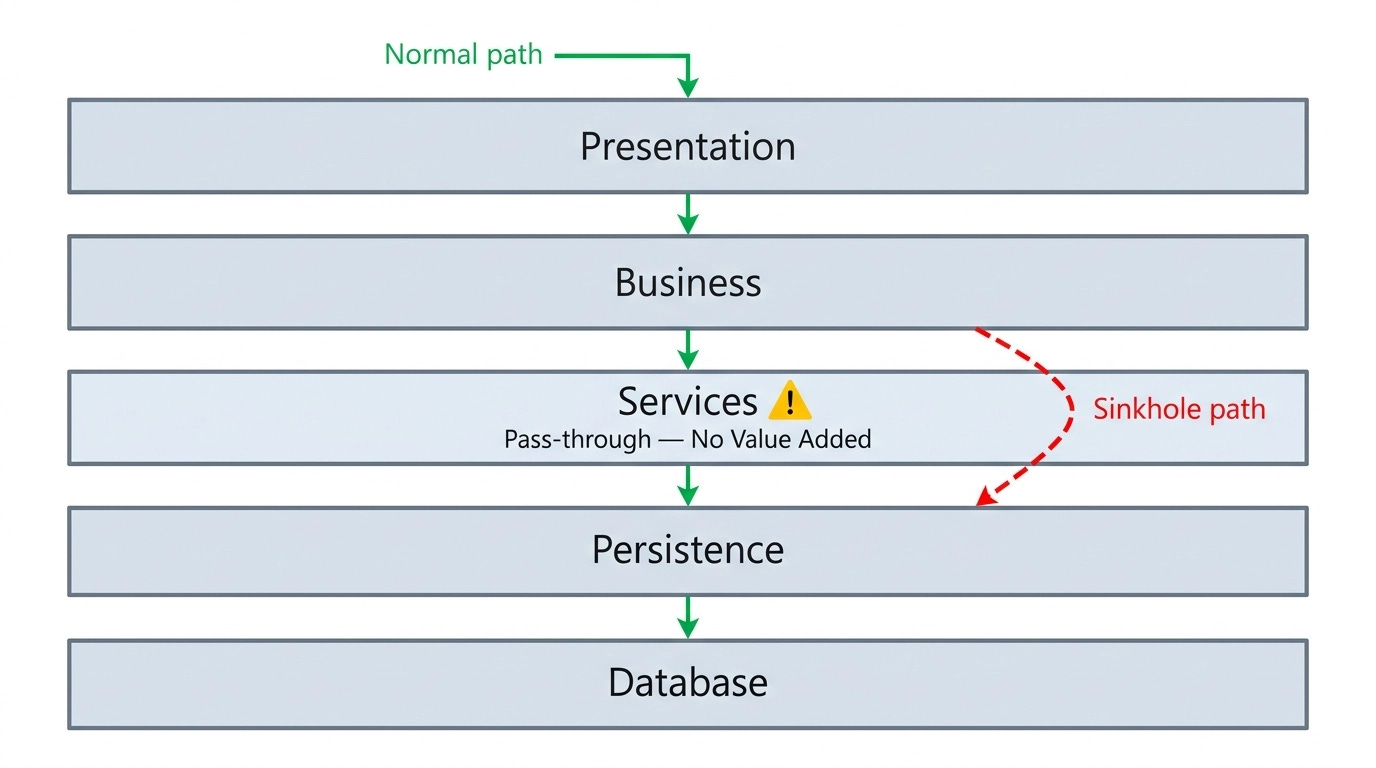
Now here’s where real-world systems get messy. As systems grow, teams often add additional layers to the classic four. A services layer between business and persistence is a common example. This is fine, as long as that layer actually does something.
The problem emerges when some requests genuinely need to pass through the services layer, and some don’t — but the architecture treats all of them the same way. Requests that don’t benefit from the services layer end up passing through it anyway, just to hop through a layer that does nothing. That’s the Architecture Sinkhole Anti-Pattern: you have states in your request pipeline that add no value for certain traffic.
The fix is to make that layer open — meaning requests can bypass it if it adds no value. An open layer is essentially optional. If you have business in the services layer, use it. If you don’t, skip it and go directly to persistence.
But — and this is the trade-off — as soon as you open a layer, you’ve increased coupling. Now both the business layer and the services layer can talk to persistence. If you need to change the persistence layer, you now have two upstream layers to worry about instead of one. Every open layer you add chips away at the isolation benefits that made layered architecture attractive in the first place. This is a trade-off you need to make deliberately, not by accident.
Death by a Thousand Tiny Cuts: Pattern Governance
Here’s a scenario every architect will face. You’ve designed a clean, disciplined layered architecture. It’s working. And then the reporting team walks in and says: “We need to generate reports at the presentation layer, and it’s too slow to go through all the layers. Can we just query the database directly from the UI?”
This is the most common test of pattern governance. And the answer has to be no.
If you allow it, you’ve fossilized the database schema into the presentation layer. You can’t change either end without touching the other. And once you allow one team to break the rules, the precedent is set. Every team with a performance problem or a deadline now has justification to take the same shortcut. Layer by layer, you drift back toward the Big Ball of Mud — just with better folder structure.
When you establish an architectural pattern, you own it. When unusual problems come up, the job of the architect is to find a solution within the pattern, not to compromise the pattern itself until it no longer exists. The right response to the reporting team isn’t “sure, bypass the layers” — it’s to find a different mechanism (a read model, a reporting service, a CQRS-style query path) that solves their problem without destroying the architecture’s integrity.
Architectural Characteristics: Where Layered Architecture Lives and Dies
Every architectural pattern has a set of characteristics it’s naturally good at and some it genuinely struggles with. Layered architecture has a pretty clear profile.
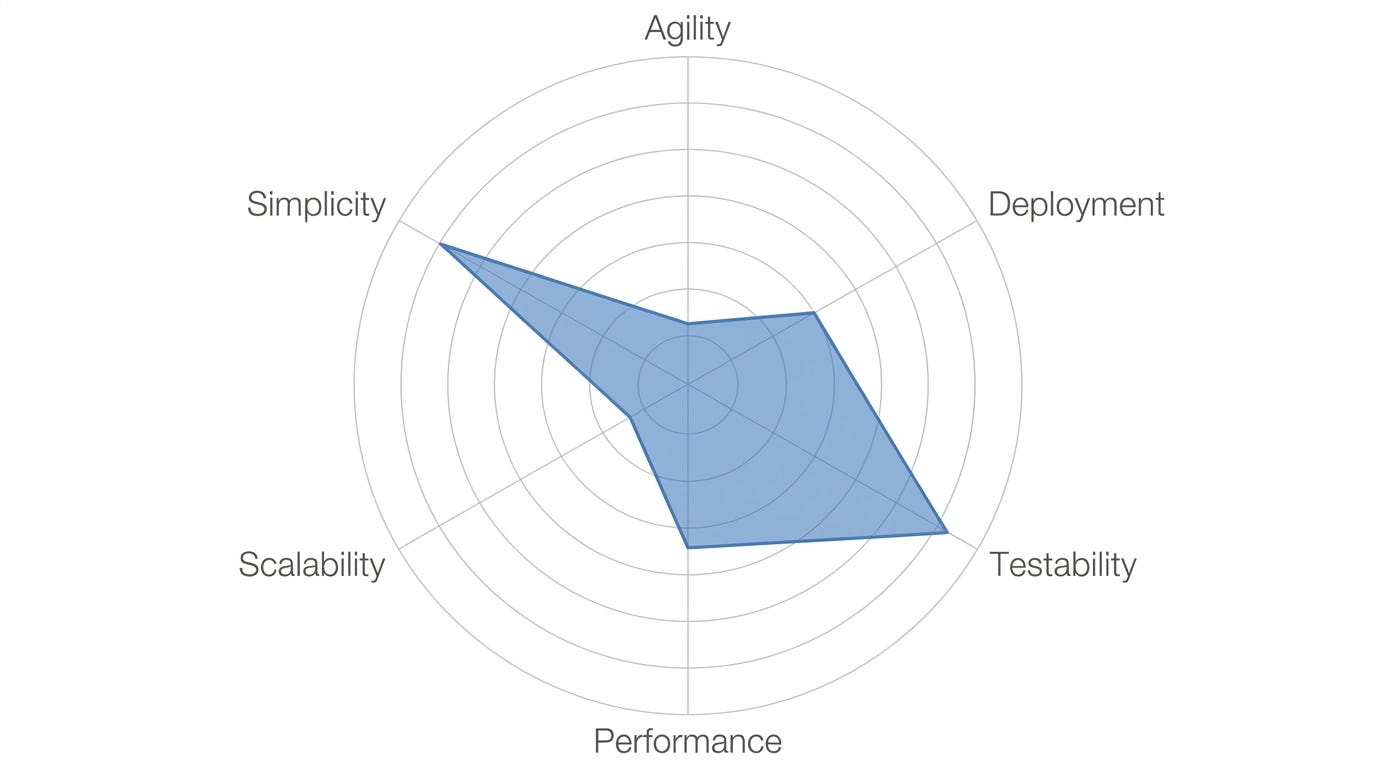
Simplicity is its superpower. Developers understand it immediately. The whole thing fits in a single project in your IDE. It’s the architecture that most teams reach for by default, not because it’s lazy, but because it’s genuinely appropriate for a wide range of problems — especially early-stage ones.
Cost is also a strength. There are very few moving parts. What’s there is visible and obvious. Building and maintaining a layered monolith is inexpensive compared to most alternatives.
Testability is better than you might expect, primarily because the industry has decades of experience with monoliths. The tooling for mocking, stubbing, and integration testing in monolithic systems is mature. Testability here scores well, not because it’s architecturally elegant, but because we’ve collectively gotten good at it.
Performance and scalability are where it starts to hurt. Small monoliths can be reasonably performant. But as the codebase grows, everything runs in the same process. As the load grows, you can’t scale one piece — you have to scale the whole thing. The bigger the system gets, the more resources it consumes, and the slower it tends to respond. These are the forces that eventually push teams toward distributed architectures.
Agility is moderate at best. Even with good separation of concerns, there’s still meaningful coupling between layers. Changing something in the business layer often ripples in ways that wouldn’t happen in a more decoupled architecture. Deploying a small change still means deploying the entire monolith.
The Sacrificial Architecture Argument
One of the most honest uses of layered architecture is as a sacrificial architecture — a deliberate, intentional starting point you expect to replace.
When you’re trying to prove a business concept, or when time-to-market is the dominant architectural characteristic, layered monolith is hard to beat. You can build it quickly. Everyone on the team understands it without much ramp-up. You can get it shipped and start generating value while you figure out what the real system needs to look like.
The key is knowing this going in. A sacrificial architecture is a conscious choice, not an accident. The problem comes when teams build a layered monolith because it was easy, never acknowledge its limitations, and then try to scale or extend it well past the point where it makes sense. That’s when the performance and scalability issues bite.
If feasibility is a dominant architectural characteristic — tight timelines, constrained budgets, uncertain requirements — the layered monolith might be exactly the right call. Not because it’s perfect, but because it’s the right tool for the current phase. The goal is to be honest about when that phase ends.
When to Reach for Layered Architecture
Layered architecture earns its place when:
The project is early-stage, and requirements are still crystallizing
The team is small, and agility within a single codebase is more valuable than distribution
The dominant architectural concern is feasibility — you need to ship, now, within budget
Testability and simplicity are more important than elasticity or horizontal scalability
You need a well-understood baseline before you can identify where the real architectural pressure points are
It’s a poor fit when scalability or agility under rapid change is the core requirement, or when multiple independent teams need to deploy changes at different cadences.
The Pattern That Anchors Everything Else
Understanding layered architecture isn’t just about knowing how to build one. It’s about understanding the tradeoffs that drove the industry to build everything that came after it. Microservices exist largely as a response to the scalability and deployment constraints of monoliths. Event-driven architectures exist to decouple components that layered architectures tightly couple. Every architectural pattern is a reaction to the limitations of whatever came before.
Layered architecture is where that lineage starts. Know it well — not just how it works, but why it works, and exactly when it stops working. That’s the knowledge that lets you make architectural decisions that actually hold up.
Part of a series based on the O’Reilly Software Architecture Fundamentals course by Mark Richards and Neil Ford. Not sponsored or affiliated — just a resource I genuinely find useful. If you want to go deeper, O’Reilly Learning offers a 10-day free trial with access to courses, books, and hands-on labs.