
Understanding Service-Based Architecture
How to Ride a Horse Before You Run a Steeplechase

Every architect who’s spent any time around a monolith has felt the pull toward microservices. The promise is intoxicating: independent deployments, elastic scale, services that evolve without dragging the rest of the system along. So teams take their twelve-thousand-class monolith, point it at microservices, and jump.
And then they fall. Hard.
There’s an architecture sitting quietly between the monolith and microservices that almost nobody talks about, and it happens to be one of the most pragmatic patterns you can put into a real business application. It’s called service-based architecture, and it deserves far more attention than it gets. If microservices is running a steeplechase, service-based architecture is learning to ride the horse first.
What It Actually Is
At first glance, the topology looks a lot like microservices. Client requests come in, hit a layer of separately deployed services, and those services do work. But three things are deliberately different, and those three differences are the whole point.
You vary the service granularity. You vary the database scope. And you vary the deployment pipeline. Get those three right and you end up with something dramatically easier to build, run, and reason about than full microservices — while still capturing most of the modularity benefits.
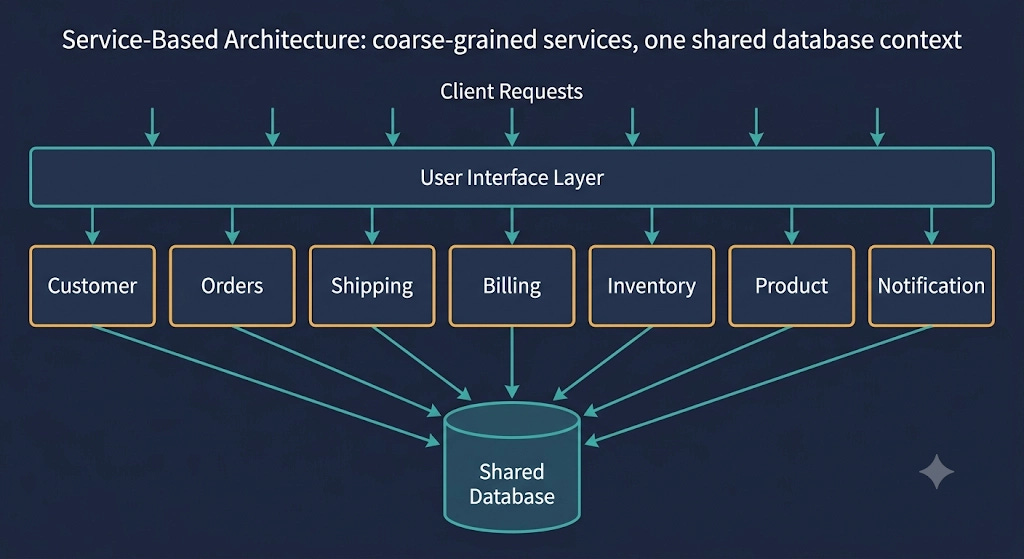
The diagram above captures the essence: a handful of coarse-grained services, fronted by a user interface layer rather than an API layer, all sharing the same database context. Where microservices might explode an application into hundreds or thousands of tiny single-purpose services, service-based architecture finds the seams in your application and splits along them — typically into somewhere between a half-dozen and a dozen services. Seven to nine is a healthy litmus test.
These services go by a few names. Some people call them application services. Some call them mesoservices — meso being Latin for “middle,” because they’re smaller than a monolith but bigger than a microservice. Others call them macroservices. The name doesn’t matter. What matters is that they’re coarse-grained, and that coarseness is a feature, not a defect.
Varying the Granularity
Think about what your application actually does. You place orders. You fulfill them. You validate them. You ship them. You track customers. That’s five clear functional areas, and in my experience there has never been a business application that can’t be carved into a half-dozen or so chunks like this. You’re not hunting for the smallest possible unit of functionality — you’re finding the natural fault lines.
The payoff for going coarse is real. Because a service now contains a lot of related business functionality and talks to a shared database, you get performance that microservices simply can’t match for certain workloads. There’s typically only one latency point — getting into the service — and once you’re in, you stay in. No chains of network hops, no aggregating a dozen REST calls just to answer a single question.
You also get domain scoping for free. Picture a microservices ecosystem with two thousand services, and someone asks you to change everything customer-related. Which of the two thousand are “customer-related”? Hope your wiki is up to date. In service-based architecture, customer logic lives in the customer service. The macro size of these services means the domain boundary is obvious.
The trade-off is coordination. A change inside a large service means coordinating with more people, and you really should test the whole service, not just your five-line change. Deployment takes more coordination too. These are genuine costs — but they’re the costs of a much simpler operational world.
Varying the Database Scope
This is the part that makes purists uncomfortable, and it’s exactly why the pattern works.
In microservices, each service owns its own data — full stop. And there’s a good reason for that discipline. If two thousand services share a database and you make a breaking change to a table that six hundred of them touch, you have to coordinate the development, testing, and release of six hundred services. Everything else grinds to a halt while you make one schema change. The bounded-context isolation in microservices exists precisely to avoid that nightmare.
Service-based architecture shares the database context anyway — and here’s the honest part: doing so does not magically eliminate the pain of breaking schema changes. What changes is the sheer number. If a breaking change hits a table used across your services, you’re coordinating three, maybe five or six services. Not six hundred. That’s a problem you can actually manage on a Tuesday afternoon.
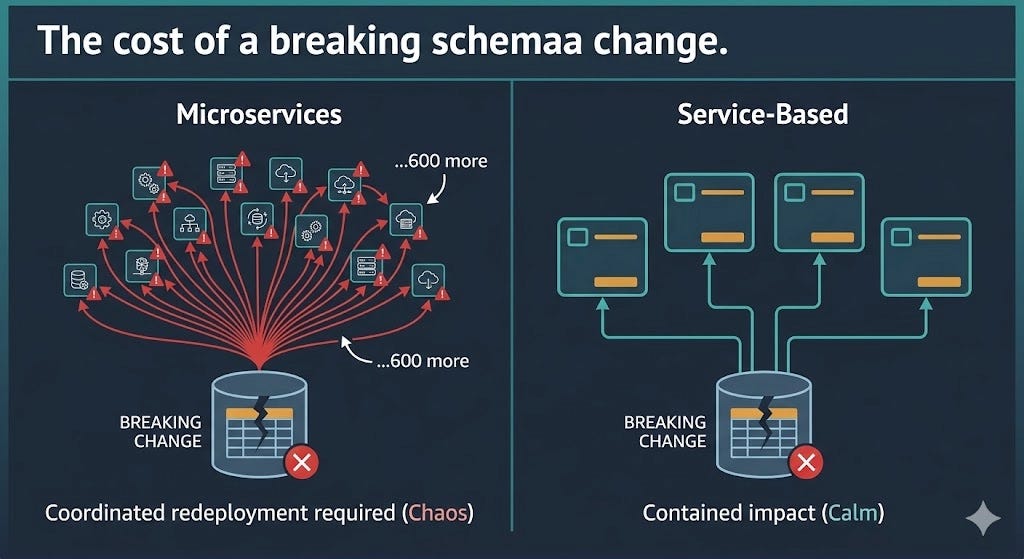
As the comparison above shows, the same schema change is a coordination crisis in one world and a minor scheduling note in the other.
And the shared database opens an opportunity microservices closes off. Suppose 300 of your tables only ever get touched by the customer-tracking service. Nobody else reads them. You can spin up a new database instance or schema, do a simple table move, and start forming bounded contexts within your service-based architecture — tightening isolation incrementally, where and when it actually buys you something.
The two big wins here are performance and feasibility. Performance, because aggregation queries — “get me all customer orders regardless of status” — are a single database call taking a handful of milliseconds, not a dozen REST calls each hitting a separate datastore. And feasibility, because the database is where most microservices migrations go to die. Teams sort out DevOps and organizational change just fine, then hit the wall of pulling apart a database into hundreds of schemas. Service-based architecture lets you keep the database whole. That alone makes it viable for organizations that could never make the full leap.
Varying the Deployment Pipeline
Here’s the advantage that ought to sell you on its own.
Microservices require DevOps. With hundreds or thousands of services, you cannot manually manage parallel deployment, testing, release, and production monitoring. Automation isn’t a nice-to-have, it’s the price of entry. The rule of thumb is that if you’re deploying more than three services by hand, you’ve already lost — and while some teams stretch to around twenty before automation becomes mandatory, the ceiling comes fast.
Service-based architecture? You get to use the same crappy deployment pipeline you have right now.
Nothing has to change. You’re taking one deployment unit and splitting it into six, seven, maybe nine separately deployed pieces. Ask yourself: in my current environment, with zero changes, can I add six or seven more WAR files, JAR files, or assemblies to my pipeline? Of course you can. It’s a bit more coordination, but there’s no DevOps mandate, no required automation tooling.
And this is where it gets clever. Once you’ve broken the monolith into a handful of separately deployed services, you can start experimenting with automation on your own timeline. Maybe you containerize one service with Docker and see how it goes. It works, so you containerize the rest. Now you wonder how to orchestrate them — Docker Swarm? Kubernetes? You try things. Maybe you swap the service-locator pattern baked into your UI for Zookeeper or Consul. Maybe you script deployments with Ansible.
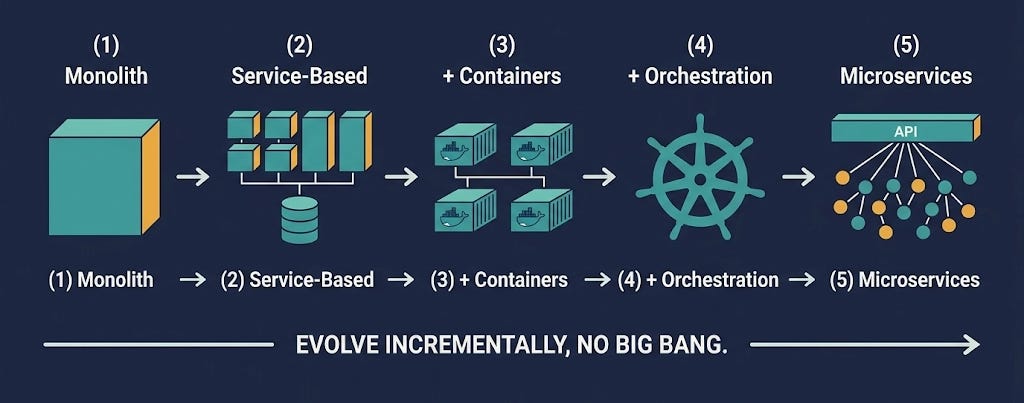
As the evolution timeline above illustrates, you’re not committing to microservices operations up front. You’re growing into them, one tool at a time, and any tool that doesn’t fit just comes back out without disrupting the whole ecosystem.
The same is true of organizational change. Microservices demand it — service owners, cross-functional teams that break Conway’s Law, genuine collaboration between developers, testers, and release engineers instead of the usual throw-it-over-the-wall relationship. That cultural shift takes six months to a year in most organizations. Service-based architecture doesn’t require any of it, but it gives you the runway to evolve toward it deliberately.
The trade-off, to be fair: your continuous delivery model stays relatively weak. You don’t have the effective, fully automated deployment pipeline that microservices give you. That’s the cost of keeping things simple.
A Real Case Study: The Recycling Monolith
Theory is cheap. Here’s what this looks like in the wild.
Picture a company that recycles electronics — you mail in your old iPhone or Samsung, they send you a postage-free box and maybe some money. It started life as a Ruby on Rails startup, grew fast, moved to the Java platform, and after about eight years had become one big n-tiered monolith with roughly 12,000 classes. A completely natural progression. Nobody set out to build a monolith; it just accreted.
Inside that monolith were clear functional regions. Quoting — how much will we give you for this device? Item status — did you receive my box, has it been accepted, did you send payment? A receiving department with its own screens and logic. An assessment region that checks whether the device works, is cracked, won’t turn on. Recycling and accounting, handling disposal or resale, the books, and reporting. The seams were right there. But everything deployed as a single unit.
That single-unit deployment caused real pain:
Testability. Assessment is the volatile region — new devices ship every month, rules change constantly. Make a change there and what should you test? Technically the whole 12,000-class application. So of course nobody does; they test the small region and hope.
Deployment risk. A failed deployment disrupts everyone — public requests, kiosks, receiving, recycling, accounting. All five user domains, every time.
Scalability. Only quoting and item status (the public-facing, kiosk-driven traffic) actually need to scale. But to scale them you pick up all 12,000 classes and heave the whole thing onto another server. That’s throughput, not scalability.
Security. Sure, there’s no code path from the 20 public screens to accounting. But there are only two kinds of companies: those that have been hacked and those that don’t know it yet. A shared monolith with a shared database is a wide-open blast radius.
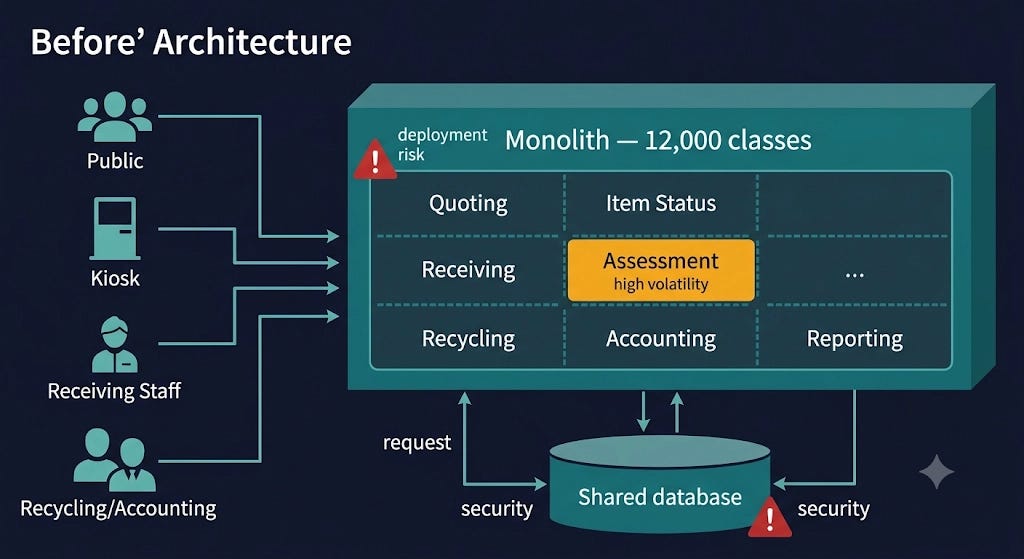
The “before” diagram above shows the trap clearly: every concern tangled into one deployable, one database, one enormous blast radius.
Now wave the wand and move to service-based architecture. Same application context, but every functional region becomes a separately deployed unit. The UI had clean seams too, so it splits into three WAR files — a public UI, a receiving UI, and a recycling UI — all still sharing the database context.
Watch what each problem does:
Scalability — quoting and item status now scale independently. Run three or four instances of each to handle public load while everything else stays at a single instance.
The UI rewrite — this company had wanted to move the public screens to a modern front-end framework for years but couldn’t justify the risk on a single deployable. Now those 20 public screens live in their own WAR. Rewrite them in Angular. Don’t like it? Try React. The rest of the system never notices.
Volatility — notice receiving and assessment are two services even though there’s one receiving UI. Why? Because the volatility lives in assessment. Splitting it out means a change to assessment only requires testing and deploying the assessment service, and a failed deployment there impacts exactly one set of users.
Security — the public UI now physically cannot reach accounting functionality. But the shared database is still a concern, so you take the quoting and item-status tables, move them to a separate database instance in a separate network zone, and now public and kiosk traffic can’t even reach the core database. For the services on the other side that still need that data, you poke a one-way hole through the firewall or set up table mirroring/replication. No path from the left side of the application to the right.
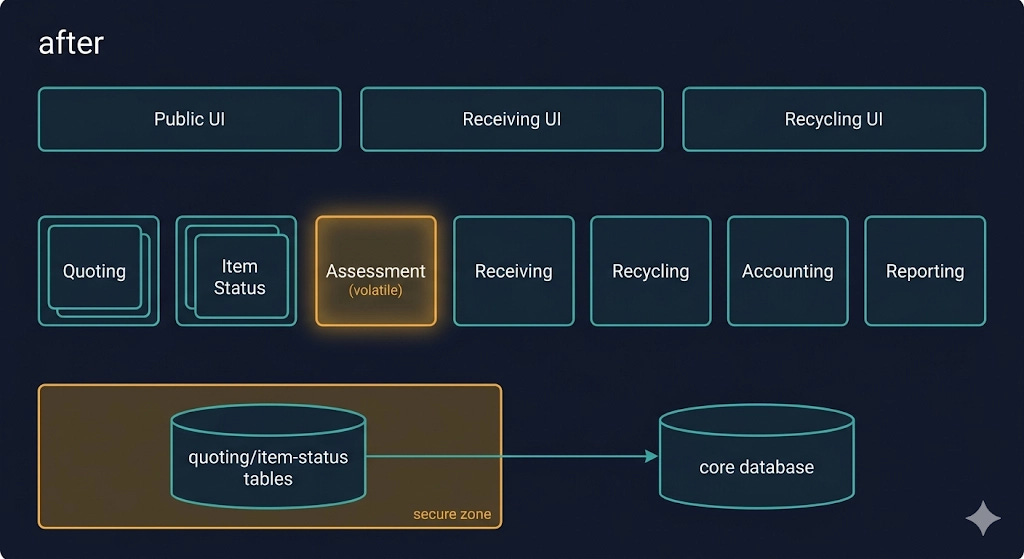
The “after” diagram above is, frankly, beautiful — not because it’s elaborate, but because every concern now has a boundary, and every boundary buys something concrete.
Why This Is the Right Path to Microservices
Here’s the question that exposes the whole thing. You have a monolith and you want microservices. You can convert one region first:
Option one: the highly volatile, high-throughput, customer-facing region — 2,000 requests a minute, ~800 operations, business-critical, changes constantly.
Option two: the admin region — adding users, agency codes, reference data — one user, one or two requests a day, ~40 operations, last changed six months ago.
Most people pick option two. It feels obviously right: minimize risk, learn microservices on the low-stakes piece. And it’s a mistake.
The only advantage of converting admin first is learnability. Every other benefit of microservices is irrelevant there. You don’t need scalability — there’s one user. You don’t need agility — it barely changes. You don’t need aggressive testability or deployment independence. So when you move admin to microservices, all you’ve done is pollute your shiny new ecosystem with services that gain nothing from being services. You’ve taken on all the complexity and captured none of the value.
The answer is to stop converting regions piecemeal and instead move the whole monolith to service-based architecture first. That’s learning to ride the horse. Find the seams, split into six or nine pieces, share the database.
Then learn to ride the horse fast: take the genuinely demanding region — the customer-facing one — and break that single macroservice into its hundred-or-so microservices, adding an API layer in front. Crucially, migrate the functionality but not yet the data. You want to validate your service granularity before you commit to physically splitting the database.
Then, and only then, run the steeplechase: complete the move to microservices, data and all, for the regions that actually justify it. Admin? Leave it as a macroservice. It’s fine. It was always fine.
This is the real argument for the pattern. Moving to service-based architecture first lets you discover which parts of your application should be microservices — which parts genuinely need the automation, agility, testability, scalability, and fault tolerance — and which parts are perfectly happy staying coarse-grained forever.
Where It Lands on the Characteristics
The ratings tell an interesting story. Service-based architecture shares the same shape as microservices on the characteristics that matter most for modularity: agility, deployability, testability, and scalability all rate well. Not as high as microservices — these are coarser services sharing a database — but clearly strong, because you’ve achieved a real level of modularity.
Where it gives ground is performance and simplicity. You’ve got RESTful calls into services, some lookups, an evolving ecosystem — so it’s not as dead-simple as a monolithic layered architecture. But it’s a fraction of the operational and cognitive complexity of full microservices.
That’s the whole proposition. You capture most of the modularity benefits of microservices, you sidestep the database explosion and the DevOps mandate and the organizational upheaval, and you give yourself a deliberate, low-risk path to evolve further if and when you actually need to. For a huge number of business applications, you’ll discover that service-based architecture is the destination — that you’ve already hit the right level of agility, testability, scalability, and deployability for your organization, and the steeplechase was never necessary.
Learn to ride the horse first.
Part of a series based on the O’Reilly Software Architecture Fundamentals course by Mark Richards and Neil Ford. Not sponsored or affiliated — just a resource I genuinely find useful. If you want to go deeper, O’Reilly Learning offers a 10-day free trial with access to courses, books, and hands-on labs.