
Understanding Pipeline Architecture

Most developers have used pipeline architecture without ever calling it that. Functional programming chains. Unix pipes. MapReduce jobs. Azure Data Factory flows. The pattern is everywhere, and once you learn to recognize it, you start seeing it in places you never noticed before.
The pipeline architecture style — also called pipes and filters — is a monolithic architecture that earns its keep through simplicity and modularity. It doesn’t give you the scalability of event-driven or the elasticity of space-based, but for a certain class of problems, it’s exactly the right tool.
Two Components, One Idea
The entire pattern rests on two building blocks: pipes and filters.
Pipes are connectors between filters. They’re unidirectional — data flows one way, there’s no request-reply. They’re typically point-to-point within a single deployment, and the payload can be anything: bytes, text, objects. The pipe doesn’t care. Its job is to move data from one filter to the next.
Filters are where the work happens. They’re self-contained, independent components. A filter doesn’t know what came before it or what comes after it. It receives input, does one specific thing to the data, and passes the result downstream. That independence is what makes the pattern so composable.
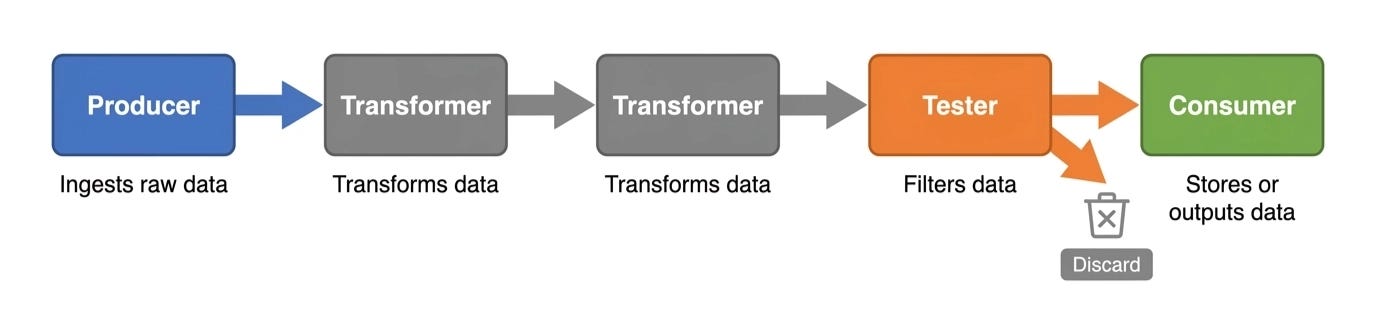
There are four types of filters:
Producers are the entry point. They have no inbound pipe — only outbound. A producer is what starts the chain. Think of a file reader, a network listener, or a database query that feeds data into the rest of the pipeline.
Transformers take data in, process it, and send something out. They’re the workhorses of the pattern. A transformer might convert JSON to XML, normalize a date format, or aggregate records. It always has both an inbound and outbound pipe.
Testers receive data and make a conditional decision: discard it or pass it along. They’re essentially filters in the literal sense of the word. A tester might check whether a record meets a certain threshold, whether an event belongs to a particular category, or whether a payload contains an error flag. If the condition fails, the data is dropped. If it passes, it moves on.
Consumers are the endpoint. They have only an inbound pipe. A consumer writes data to a file, pushes it to a database, sends a notification, or hands it off to another system entirely.
A Concrete Example
Say you’re building a clickstream analysis tool that captures web events, processes them, and writes results to multiple destinations. Here’s how that might look in a pipeline architecture.
You start with a Text Capture producer that reads raw event data from your web server logs. That feeds through a Text Converter transformer that normalizes the text into XML. The converted data flows into a Processing Engine transformer — your MapReduce or aggregation logic — that produces structured analytical output. From there, a File Output Tester checks whether this batch should be written to disk. If no, the data is discarded. If yes, it flows to a File Consumer that persists it.
Now you need to also capture JSON events from your mobile app. You add a JSON Capture producer and a JSON Converter transformer that converts to the same XML format, then merges into the same Processing Engine. No changes to existing components. You just plugged in new producers and transformers upstream.
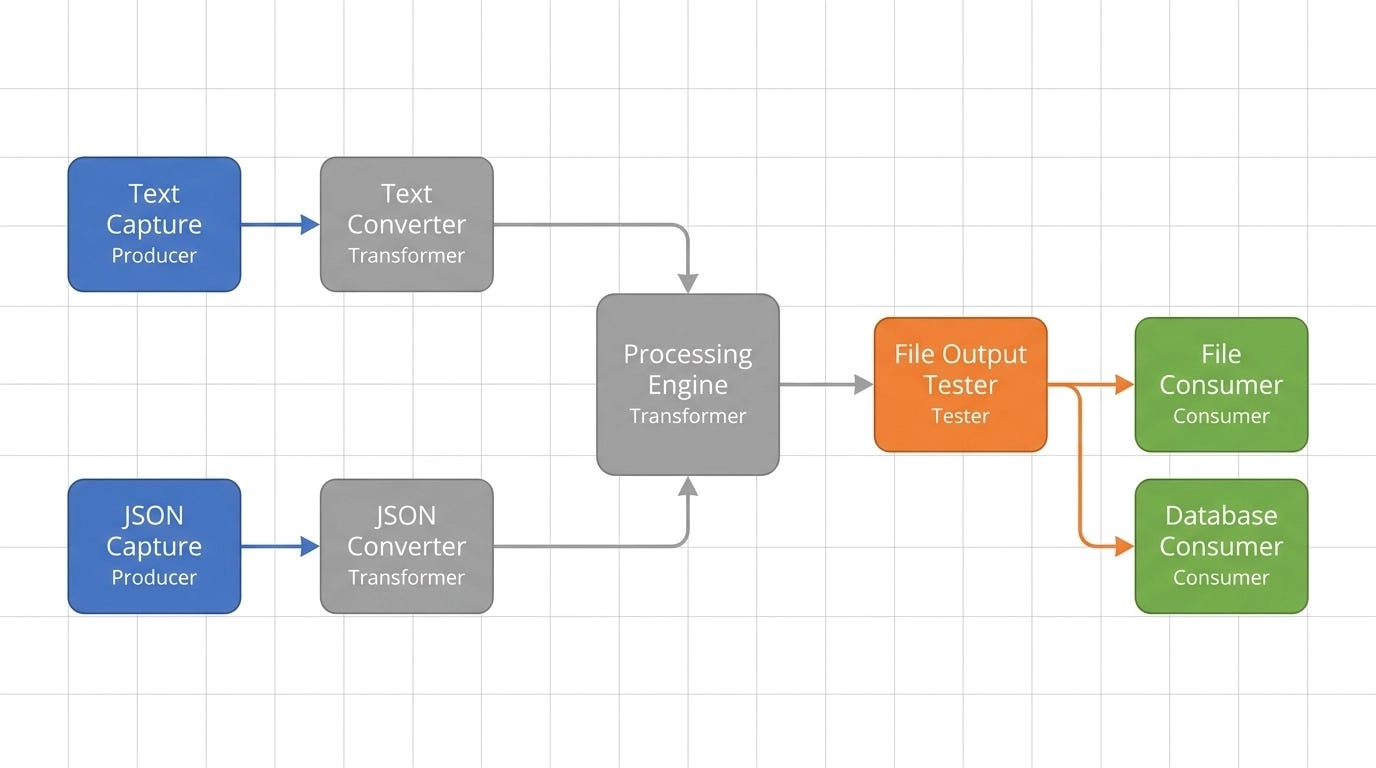
Later you need to add a database output alongside the file output. You add a second tester and a database consumer downstream. The rest of the pipeline is untouched. This is the evolutionary nature of the pattern — each component is independent, so you can grow the pipeline incrementally without reworking what already exists.
Pipeline vs. Event-Driven: Not the Same Thing
A question that comes up naturally: if you’re passing data between components through connectors, isn’t this just event-driven architecture?
No. The two patterns look similar at a glance but serve fundamentally different purposes.
Dimension Pipeline Event-Driven Processing model Synchronous data filtering Asynchronous event processing Communication Uni-directional only Can be request-reply Filter purpose Single, specific task Complex, multipurpose Deployment Typically monolithic Distributed
Pipeline architecture is about moving data through a chain of discrete transformations in sequence. Event-driven architecture is about reacting to things happening in a system, often in parallel across many consumers. You could wire messaging infrastructure between your filters and end up with something event-driven, but that would be a hybrid — a deliberate architectural decision, not the pipeline pattern itself.
Characteristics at a Glance
Pipeline architecture sits in an interesting position among the patterns. It’s solidly in the monolith category, which gives it some limitations, but it compensates with high modularity and simplicity.
Agility and testability both rate well. Because each filter is independent and has a single responsibility, you can test them in isolation with ease. If a requirement changes, you can swap out a transformer or add a tester without touching the rest of the pipeline. The architecture responds well to incremental change.
Deployability gets a thumbs down — not because it’s difficult to deploy, but because multiple filters are typically bundled in a single deployment unit, which raises the risk profile compared to deploying a single isolated service.
Performance and scalability also rate low as architectural characteristics. That doesn’t mean pipelines are inherently slow — they can be very fast. It means the pattern itself doesn’t lend towards horizontal scaling or high-throughput distributed processing. If you need to handle massive parallelism, event-driven or space-based architectures are better choices.
Simplicity and cost are strengths. No special frameworks required. No distributed infrastructure to manage. The pattern is easy to understand, straightforward to implement, and cheap to maintain.
Where You’re Already Using This
The pipeline pattern shows up throughout the software ecosystem in ways you probably already use:
MapReduce is a pipeline architecture. Data flows through map, shuffle, and reduce stages as discrete transformations. Functional programming chains — map, filter, reduce — are a direct expression of the same idea. Azure Data Factory pipelines, ETL frameworks, and most data processing tools are built on this pattern. The shell’s pipe operator (|) is the most literal expression of it.
When you see a workflow that ingests raw data, applies a series of transformations, applies conditional filtering, and writes results to one or more outputs — that’s a pipeline. Naming it correctly matters because the pattern tells you what it’s good at, what it isn’t, and how to evolve it without breaking what already works.
Part of a series based on the O’Reilly Software Architecture Fundamentals course by Mark Richards and Neil Ford. Not sponsored or affiliated — just a resource I genuinely find useful. If you want to go deeper, O’Reilly Learning offers a 10-day free trial with access to courses, books, and hands-on labs.