
Understanding Microservices Architecture

There’s a sign you see at carnivals: You must be this tall to ride. The microservices community has its own version of that sign, and the height requirement is steep. You need continuous delivery pipelines, automated machine provisioning, mature service discovery, aggressive testing practices, and a team culture that treats operational concerns as first-class engineering work. If you don’t have those things yet, microservices will punish you for it. If you do, you unlock something genuinely powerful.
Microservices earned their popularity through real results at companies like Amazon and Netflix — systems that needed to scale to a level where traditional architectural patterns simply broke down. This isn’t hype architecture. But it’s also not for everyone, and understanding why requires a clear look at what the pattern actually is, not just what people say it is.
What Microservices Actually Means
The name is a label, not a description. That’s an important distinction. When the term was popularized, the goal was to contrast it with service-oriented architectures — which tended toward massive, coarse-grained services. Micro was chosen to emphasize the contrast, not to mandate that every service be tiny. Some legitimate microservices are quite large.
The real driver is the concept of a bounded context, borrowed from domain-driven design. A bounded context is a business process — not an entity. “Customer” is not a bounded context. “Catalog checkout” is. The distinction matters because it changes how you partition your system. You’re not decomposing around data shapes; you’re decomposing around business capabilities that can own their own data, their own persistence, and their own lifecycle.
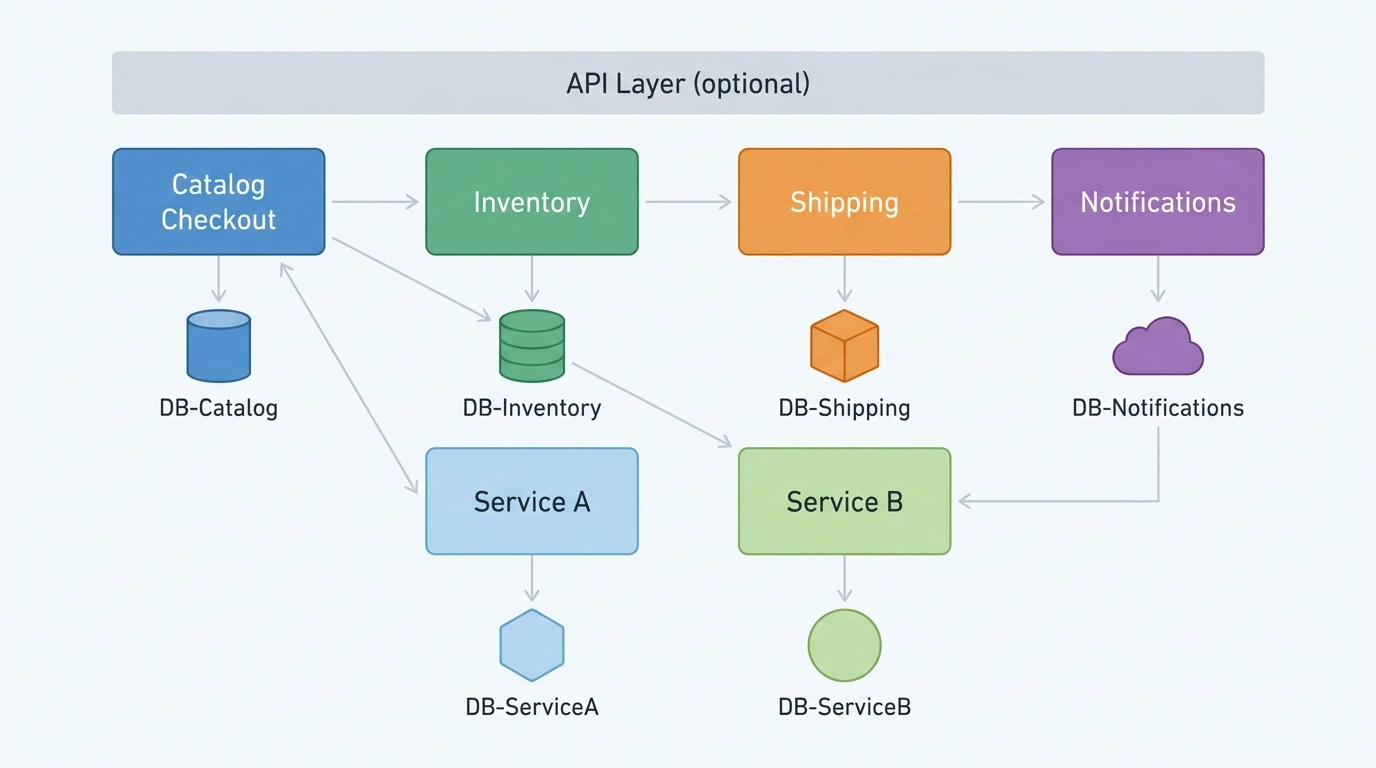
Each service in this architecture is a LEGO. Everything it needs comes along when you install it, and when you remove it, every trace of it disappears from the system. That complete operational isolation is the source of microservices’ superpower — and its cost. The diagram below shows what this looks like structurally: an optional API layer sitting in front of independently deployed services, each sitting on its own isolated data store.
No Middleware, By Design
Microservices are a distributed architecture. Each service runs in its own process space, communicates via HTTP/REST, SOAP, or asynchronous message queues, and is individually deployed. There is deliberately no central mediator.
That last point trips people up. Event-driven architectures often have a mediator — something that coordinates workflow across processors. Microservices don’t. The reason is that the bounded context principle requires all important workflows to live inside one of those services. Smearing business logic across an integration bus violates the principle and recreates, in a new form, the very coupling you were trying to eliminate.
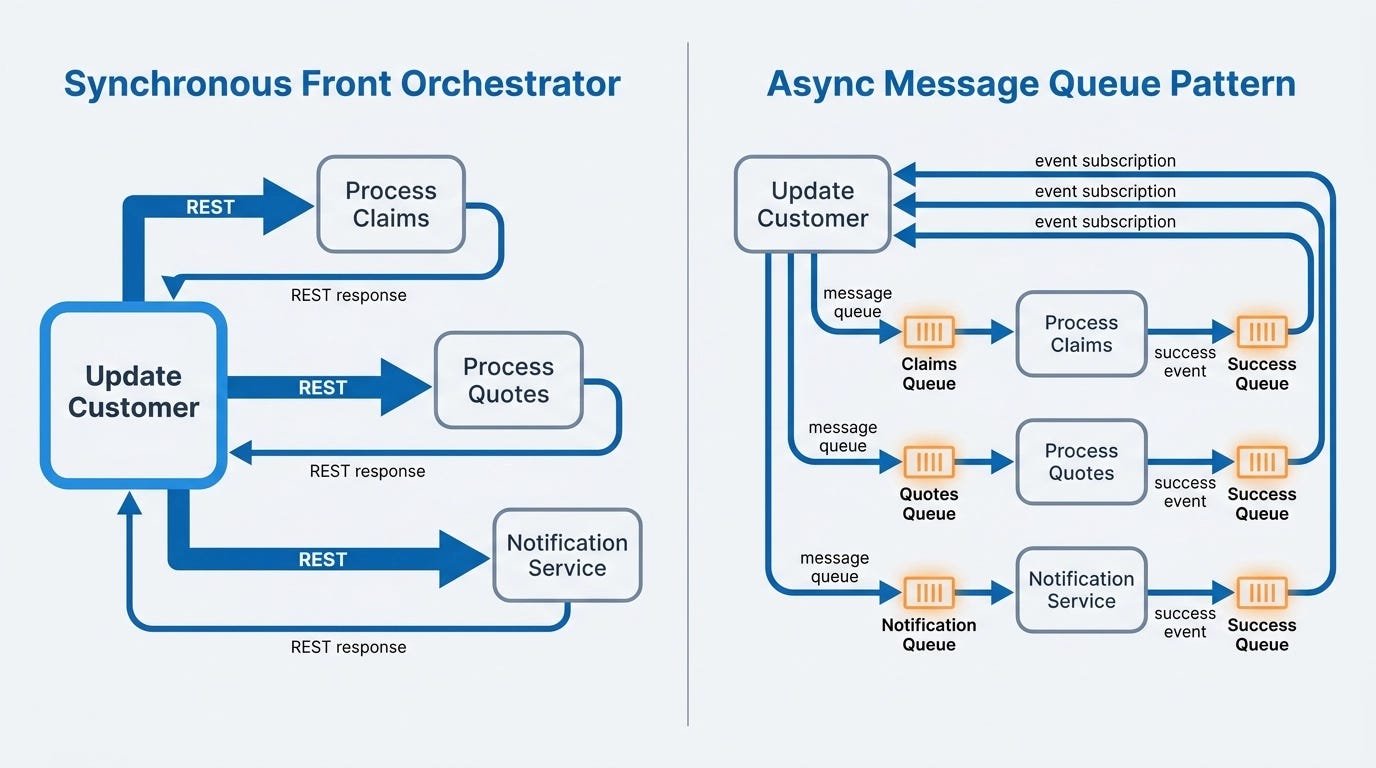
This creates a coordination problem. When you call “update customer” and several downstream things need to happen — update quotes, update claims, send a notification — someone has to orchestrate that. In the absence of a mediator, that responsibility typically falls on a “front orchestrator,” the first service in the chain. It knows the workflow, calls the subsequent services, and gathers results. It’s not elegant, but it keeps business logic within a bounded context.
Whether those calls are synchronous or asynchronous is a separate decision. Synchronous gives you certainty: you know whether downstream steps succeeded before moving on. Asynchronous gives you scale and throughput. Both patterns are valid, and the fire-and-forget approach with message queues works well when you don’t need tight transactional coordination. The two patterns are compared side by side in the diagram below.
The Service Template: Solving Cross-Cutting Concerns Without Coupling
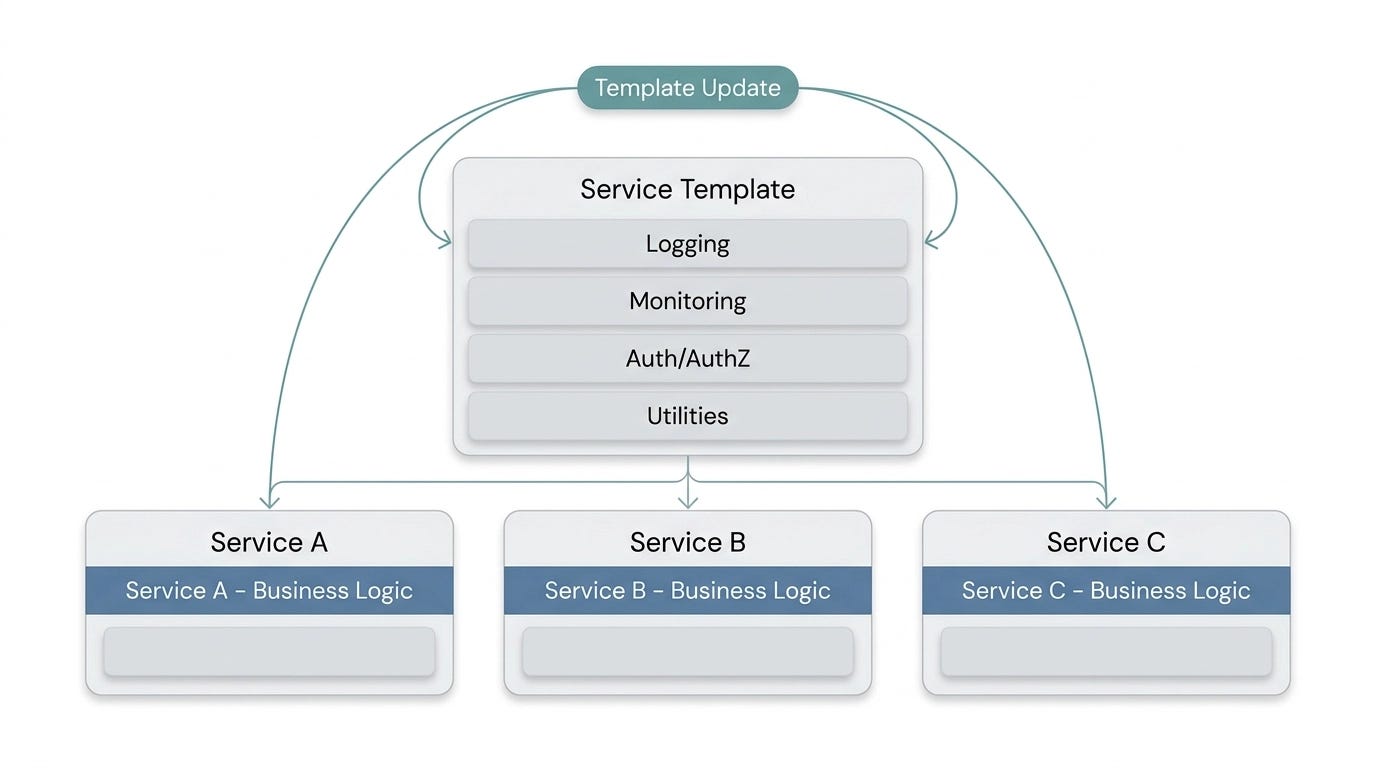
One of the practical problems with dozens or hundreds of independent services is consistency. Every service needs logging, monitoring, authentication, and other infrastructure concerns. Managing those across independently evolving teams is a coordination nightmare — you can’t send someone door to door to upgrade a logging library.
The service template solves this. Instead of each team building their service from scratch, they extend from a shared template that already includes the infrastructure baseline. Monitoring, logging, authentication — all pre-wired. When the monitoring library needs updating, you update the template. The next time each service builds, it picks up the new version automatically. The diagram below shows how that structure works: a shared template layer that each service inherits from, with their own business logic sitting on top.
The service template also addresses the famous microservices mantra: “duplication is preferable to coupling.” That phrase sounds extreme out of context. What it actually means is: don’t create shared domain classes that multiple services depend on, because that coupling prevents independent evolution. But plumbing code — JSON/XML conversion, common authentication flows, utility functions — that belongs in the template, not duplicated everywhere. The mantra is about avoiding inadvertent coupling, not about copy-pasting infrastructure code across every codebase.
The Database Problem
The database situation is where most microservices migrations hit reality. The ideal is clear: each service owns its own data store, with no shared databases. That isolation is what enables truly independent deployment — if two services share a schema, a change to that schema couples their deployments.
In practice, breaking apart a decade-old enterprise database into isolated service-owned stores is a significant undertaking. DBAs who have spent years building a carefully normalized schema are not going to cheerfully decompose it into hundreds of pieces. And they’re not wrong to push back — the data coordination problems that emerge from total isolation are non-trivial.
The common compromise is shared databases among a small cluster of tightly related services, accepting that you’ve increased coupling in exchange for pragmatism. The danger is that this compromise, unchecked, migrates back toward a single shared database — at which point you have all the complexity of microservices with none of the isolation benefits.
Be intentional about where you compromise. If you compromise everywhere, you’ve built a distributed monolith: the worst of both worlds.
The API Layer
Almost every microservices diagram includes an API layer, and there’s good reason for it — but it’s often misunderstood. The API layer is not a mediator. It should not contain business workflow or orchestration logic. If it does, you’ve essentially built an Enterprise Service Bus under a different name, and you’ll end up with the same organizational bottleneck problems.
What the API layer legitimately does is facade management: hiding internal endpoints, exposing only what you want public consumers to see, and handling concerns like load balancing or endpoint proxying. It can also implement the back-end-for-front-end pattern — separate API layers optimized for different clients (iOS, Android, browser) rather than one giant switch statement trying to serve all of them.
For legacy integration, the API layer can also act as a protocol bridge — wrapping disparate legacy endpoints so they look like services, without requiring you to rewrite anything. That’s a pragmatic path to a gradual microservices migration.
Performance, Scalability, and the Cost of Distributed Everything
Microservices does not score well on performance. When you enforce bounded contexts, information has to travel at the network layer. Every cross-service call adds latency. Systems that heavily coordinate across services will feel this.
Scalability, however, is where this architecture is unmatched. Because services are operationally isolated, you can apply elastic scale surgically. If one service handles a high-volume, latency-sensitive operation, you scale that service independently. The engineering investment in resilience and scale stays contained to the service that needs it, without affecting every other service in the system.
This per-service characteristic setting is a fundamental shift from every other architecture we’ve looked at. In a monolith, your architectural characteristics — scalability, auditability, reliability — apply to the whole system. In microservices, they apply per bounded context.
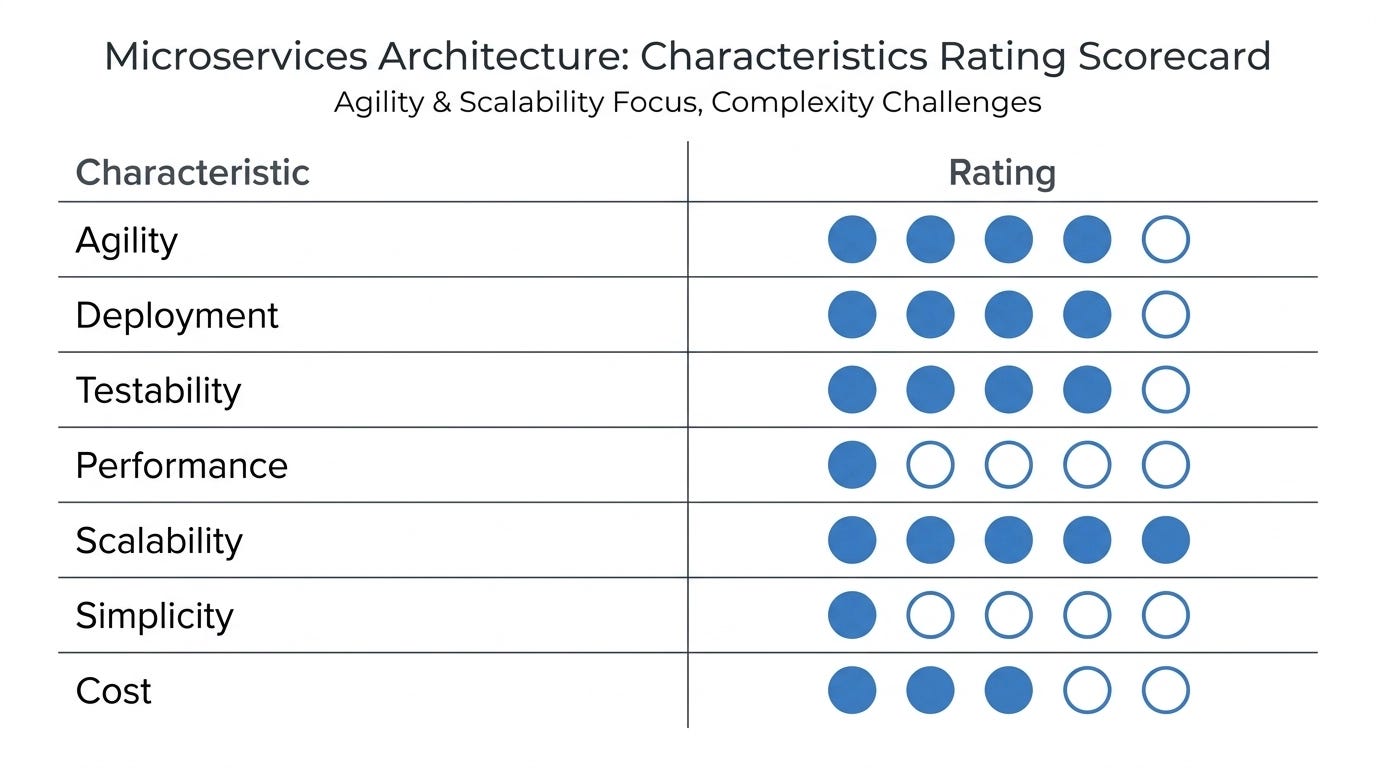
Agility is exceptional once the system is up and running. A small, well-scoped change deploys in one service, touching nothing else. That’s the gateway to the kind of iterative delivery cadence that traditional architectures make extremely difficult. The scorecard below summarizes how microservices ranks across the key architectural characteristics — exceptional scalability and agility, at the cost of simplicity and raw performance.
The Upfront Cost
One interesting observation about microservices is where the pain tends to concentrate. Traditional Service-Oriented Architecture projects accumulated complexity at the end — everything was running around like they had hair on fire, trying to get it all deployed. Microservices front-loads that pain. You have to get deployment pipelines, service discovery, machine provisioning, and automated testing infrastructure in place before you build significant features.
That’s uncomfortable. But it’s also the pattern working as intended. The upfront investment in automation means that once the machinery is running, you can keep making changes at high velocity with a relatively low ongoing overhead. The chaos doesn’t arrive at the end; it gets absorbed into the infrastructure from day one.
One colleague put it succinctly: if you’re deploying more than three services by hand, you’ve already lost. Automation isn’t optional — it’s the architecture.
Reporting in a Microservices World
Reporting is one of the most commonly botched parts of microservices implementations. The naive approach — a reporting service that queries every other service for data — produces the slowest possible architecture. You’re making network calls to every service, aggregating at the application layer, and paying for the isolation costs without getting the isolation benefits.
The right pattern separates reporting entirely. System of record is one concern; reporting is a completely different concern. Events flowing into the architecture get streamed to de-normalized reporting databases optimized for queries, while system-of-record services handle writes. The two never share storage. It’s an eventual consistency model — there’s a lag — but that trade-off is almost always worth making.
This pattern works because microservices is fundamentally an eventually consistent architecture. You need to embrace that. Trying to impose transactional guarantees across service boundaries leads to distributed rollbacks, which are one of the hardest problems in distributed systems. If you find yourself saying “we need a distributed transaction here,” take a step back and find a different partition.
What You’re Trading
Microservices are not universally the right choice. The simplicity score is poor — each individual service is simple, but the number of services, the coordination between them, and the operational infrastructure complexity add up to a system that is difficult to reason about end-to-end. The cost is moderate to high, especially in the early phases.
It’s the right choice when you need extreme scale, when you have the engineering maturity to support it, and when the business demands the kind of independent deployment velocity that only this architecture provides. If your architectural characteristics point toward agility, scalability, and deployability, microservices are a strong fit. If your constraints are budget, timeline, or organizational maturity, a different pattern will serve you better.
The architecture grew up in the context of organizations that had solved operations. Teams like Netflix and Amazon had built the operational machinery that made elastic scaling and automated deployment routine. Microservices assume you have that, or that you’re committed to building it. Without it, you’re carrying the complexity without capturing the benefit.
Know what you’re signing up for. Build the machinery first. Then build the services.
Part of a series based on the O’Reilly Software Architecture Fundamentals course by Mark Richards and Neil Ford. Not sponsored or affiliated — just a resource I genuinely find useful. If you want to go deeper, O’Reilly Learning offers a 10-day free trial with access to courses, books, and hands-on labs.