
Understanding Event-Driven Architecture

Every architectural pattern we’ve looked at so far — layered, microkernel, pipeline — runs inside a single process. Event-driven architecture is the first one that doesn’t. This is a distributed architecture, which means components run in separate process spaces, communicate across a network, and don’t share memory. That changes everything: the coupling model, the failure model, the testing model, and the way you think about workflow.
EDA comes in two distinct flavors — broker topology and mediator topology — and knowing the difference between them is what separates an architect who’s made an informed decision from one who just reached for the first message queue they found.
The Shared Foundation
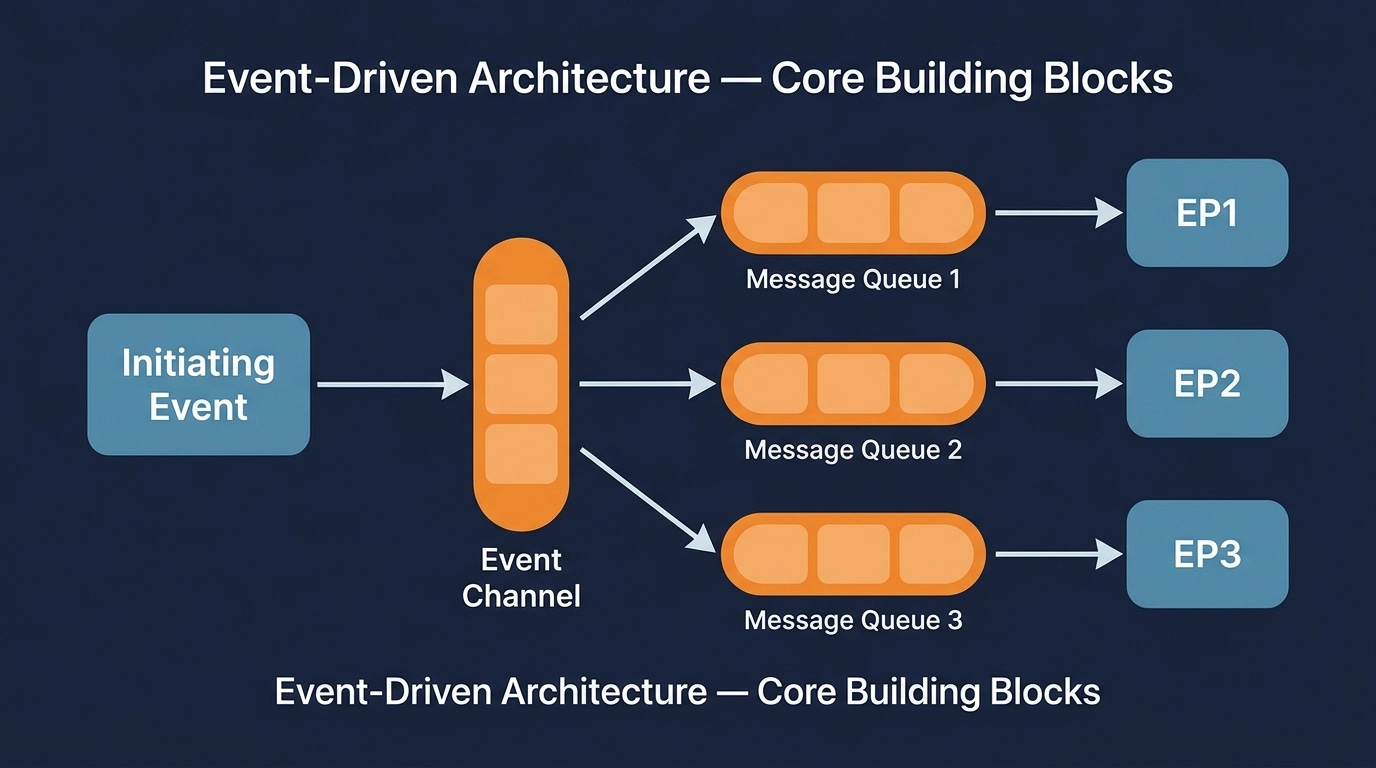
Both topologies share the same basic plumbing: events, message queues, and event processors. An initiating event kicks off a process. Event processors are the components that do actual work. Message queues (or channels) are the connective tissue. An event processor handles an event, potentially produces a new event, posts it to a queue, and other processors that care about that event pick it up and react.
What varies between the two topologies is whether there’s a central coordinator in the mix.
Broker Topology: Parallel Speed, No Coordinator
In a broker topology, there is no central brain. You fire an event, it lands in a queue, and whoever is subscribed picks it up and does their thing. Each processor is autonomous. When it finishes, it may publish a new event to another queue, and the chain continues.
The classic example: an insurance customer moves. That generates a “customer moved” event, which gets picked up by the customer processor — it updates the address in the system of record and publishes a “change of address” event. Both the quote processor and the claims processor are subscribed to that channel. They pick it up simultaneously and run in parallel. The quote processor recalculates outstanding quotes and fires off a notification event. The claims processor updates any affected claims and fires off an event that both the adjustment processor and the notification processor care about.
The whole process fans out and runs concurrently. No one is waiting for anyone else. That’s the entire point.
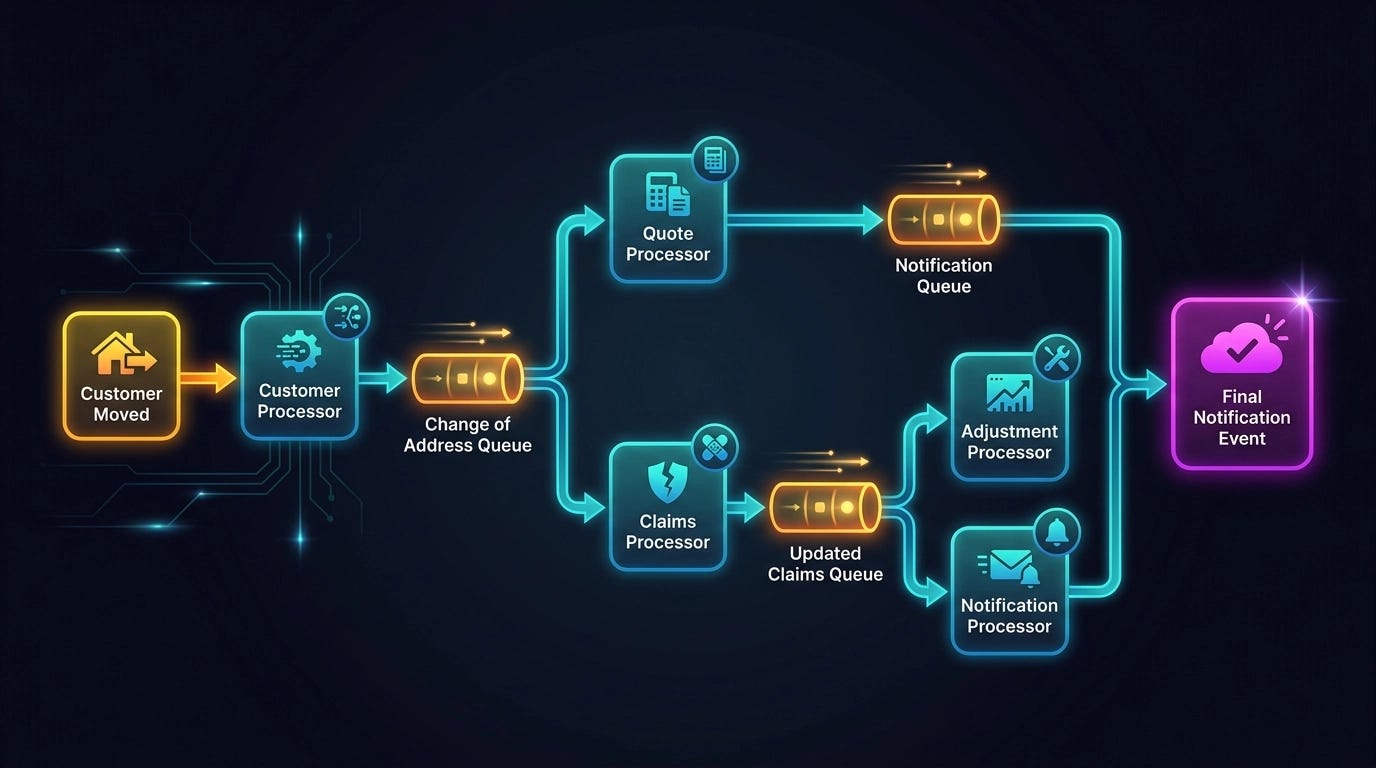
This architecture has serious strengths. Broker topology is highly agile because extending it is trivial — you want to add an audit trail every time a claim is updated? Just wire up an audit processor to the existing queue. No changes to any existing component. Everything else keeps running as-is.
But the weaknesses are just as real. Three problems stand out:
Error handling. If the claims processor crashes halfway through and never publishes to the downstream queue, nothing happens. The adjustment and notification processors never fire. There’s no central overseer to notice. You have to build your own error-handling infrastructure — dead-letter queues, retry mechanisms, compensating events. The responsibility falls entirely on you.
Coordination. This is a deeply asynchronous system. There is no concept of “wait for all of this to finish before doing the next thing.” If you want to send a single unified email to the customer rather than three separate ones, the notification processor has to implement that intelligence itself — buffer events for a time window, correlate by customer ID, then emit a consolidated message. In a broker topology, coordination always happens at the end, because that’s the only place where something has enough context to do it.
Observability. Tracing what happened to a given request across a chain of asynchronous events is non-trivial. Two techniques help: synthetic transactions (tagged events that traverse the full workflow but are discarded at the last step rather than committed) and correlation IDs (a unique identifier attached to the originating event that propagates through every processor, making the entire chain traceable in logs).
Broker topology is the right choice when parallelism is the point. Commodity trading systems, real-time pricing engines, high-throughput event streams — these are the problems this pattern was built for. You’re accepting the coordination tax in exchange for raw parallel throughput.
Mediator Topology: Coordination at the Front
If you need transactional-looking behavior in a distributed system, or you want error handling in one place instead of scattered across dozens of processors, the mediator topology is the answer.
The mediator is a central component — it could be Spring Integration, Apache Camel, Mule, an Enterprise Service Bus, or a BPM/BPEL engine. Every initiating event goes into the mediator. The mediator knows the business workflow, publishes messages to the appropriate queues in the right order, and monitors what comes back.
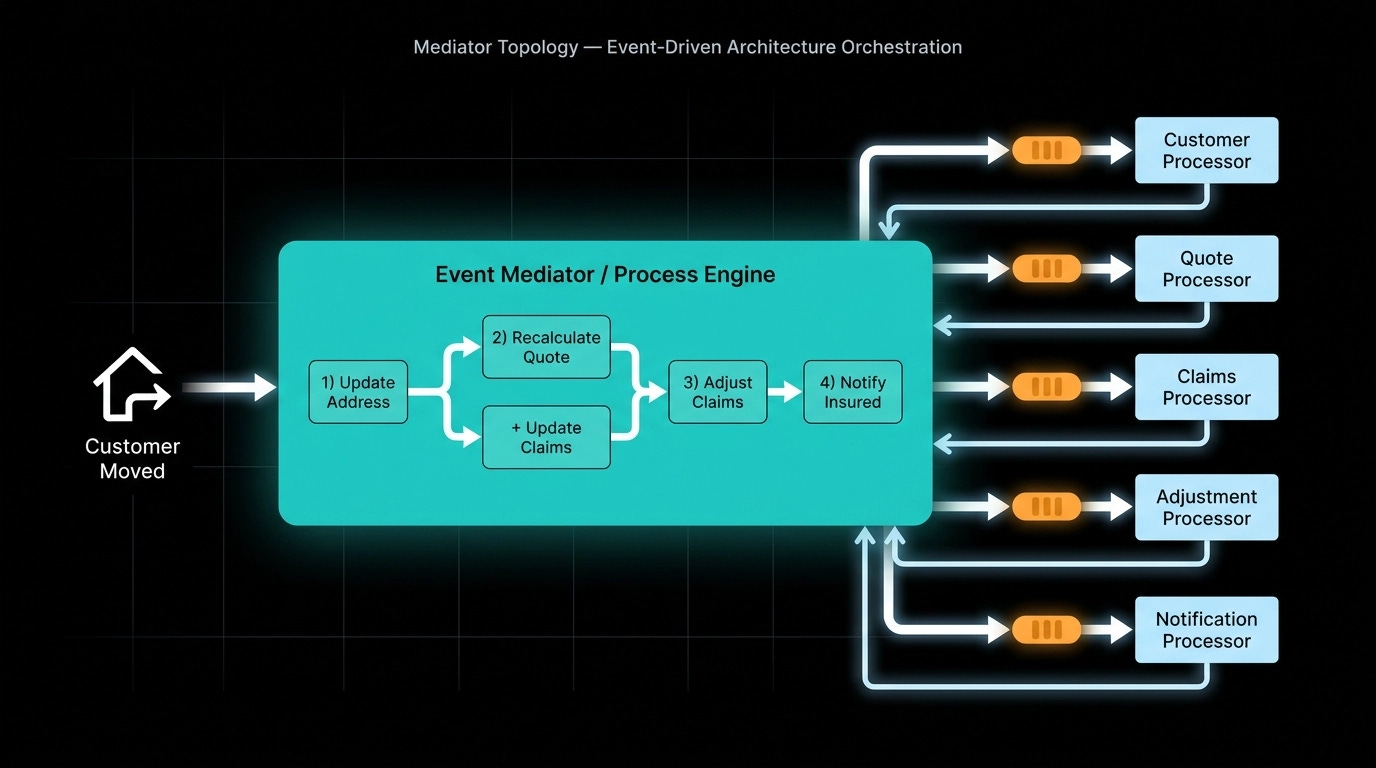
Going back to the insurance example: the “customer moved” event hits the mediator, which drives through the same workflow — update address, recalculate quote, and update claims in parallel, adjust claims, notify the insured. The difference is that the mediator knows when each step is completed before moving to the next. It can implement checkpoints: “make sure both recalculate quote and update claims succeed before triggering adjustment.”
This solves the three problems from the broker topology directly:
Error handling. The mediator owns it. If a processor fails to acknowledge a step, the mediator notices and can retry, compensate, or escalate.
Coordination. Because the mediator has sequenced the workflow and knows when “notify insured” can fire, it knows all the prior steps have completed. Generating a single unified email is trivial — by the time you reach that step, everything else is done.
Workflow clarity. The business process is explicit and centralized. Anyone reading the mediator configuration can understand the end-to-end flow.
The trade-off is evolution. If you need to add an audit process to the claims step, you can’t just wire a new processor onto an existing queue like you can in the broker topology. You have to add the audit processor and update the mediator to include it in the workflow. Two changes instead of one. That compounds as the system grows.
There’s also an organizational gravity problem rooted in Conway’s Law. The moment you introduce a mediator, you create a team to own it — integration architects or a platform team. That team becomes a bottleneck. Every new business workflow has to go through them. The mediator accumulates scope, the team accumulates scope, and you’ve inadvertently built a centralized monolith around your distributed coordinator. This is the exact failure mode that gave traditional SOA and Enterprise Service Buses such a bad reputation.

Neither topology is objectively better. Choose a broker when parallelism is the overriding concern, and you’re willing to own the coordination complexity at the edge. Choose a mediator when the workflow has real sequencing requirements and transactional-looking guarantees matter more than peak throughput. And consider hybrid: nothing stops you from using a mediator for the parts of your system that need coordination, while using broker topology for high-throughput fan-out paths where parallelism wins.
CQRS: When Events Meet Data
Event-driven systems intersect naturally with a pattern called CQRS — Command Query Responsibility Segregation, formalized by Greg Young. The core insight is that reading data and writing data are fundamentally different operations with different engineering characteristics, and conflating them into a single mechanism usually works against you at scale.
In a traditional setup, the same database serves both writes (system of record) and reads (reporting and queries). Under load, these two workloads compete for the same resources, often with incompatible indexing and consistency requirements.
CQRS splits them. Writes go to an update database — the system of record. Reads come from a separate query database, populated asynchronously by a background replication process. The update side is normalized and consistent. The query side is denormalized and optimized for the read patterns you actually have.
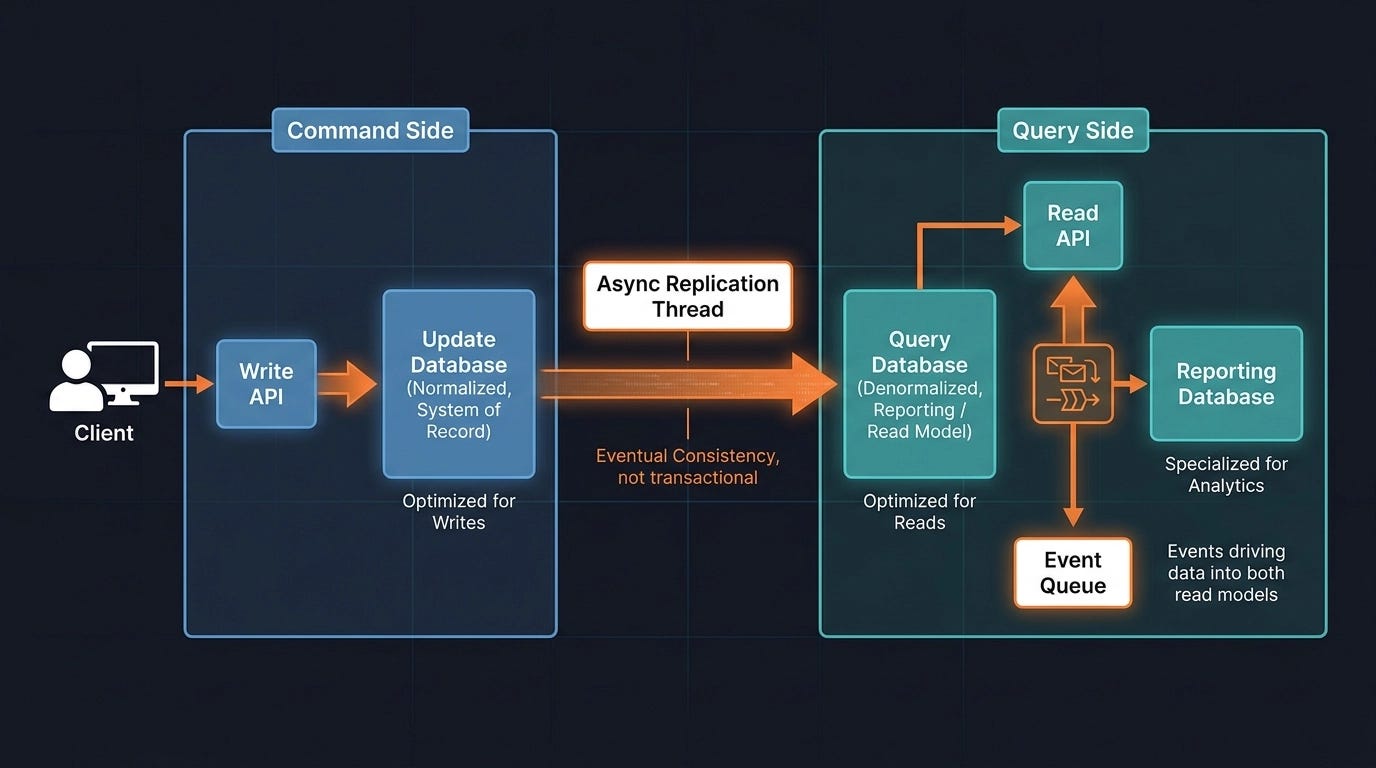
The important caveat: this is an eventually consistent system, not a transactional one. The query database will be slightly behind the update database, always. If that’s a dealbreaker for your use case, CQRS isn’t the right tool. But at a large scale, you’re often forced into eventual consistency anyway — the question is whether you’re doing it intentionally or accidentally.
Events make this pattern clean. Instead of direct database replication, write events go to an event queue. The queue feeds both the system of record and the reporting database. Services that only read have no idea where the data came from or how it got updated — they just query a database that always has a current-enough view of the world. In microservices architectures, especially, this is a much healthier alternative to building a reporting mechanism that reaches across every service, aggregating data over the network.
Characteristics at a Glance
Event-driven architecture scores well on agility (particularly broker topology — adding new behavior is cheap), performance, and scalability. Deploying to message queues is mostly turnkey. But testing scores poorly across the board: highly asynchronous systems are genuinely difficult to test realistically, and this doesn’t get easier with experience. Synthetic transactions and correlation IDs help, but the investment is real.
Simplicity is also a weakness. Broker topology in particular places a heavy cognitive load on developers, because the distributed coordination responsibility is diffuse. You need developers who understand what they’re signing up for. Cost reflects that complexity: this is not a cheap architecture to run well.
Part of a series based on the O’Reilly Software Architecture Fundamentals course by Mark Richards and Neil Ford. Not sponsored or affiliated — just a resource I genuinely find useful. If you want to go deeper, O’Reilly Learning offers a 10-day free trial with access to courses, books, and hands-on labs.